几年前介绍过一种基于zk的分布式锁1的实现,那种是没有经过实践证明的,听过一场分享,然后觉得原来分布式锁可以这么搞,然后在实验环境写了一些代码,简单验证一下,就认为成了。其实那里面有几个比较严重的问题,第一个是锁操作如果在并发的情况下不是block的,而是通过循环+sleep的方式来反复判断,性能上是比较差的,不够实时。第二个是设计太复杂,其实可以不需要ip地址的介入的。
基于zookeeper,其实可以设计出优雅的分布式锁。这个锁可以有这几个API:lock(), unlock(), isLock(),lock用于加锁,unlock用于解锁,isLock用于判断是否已经锁住了。zookeeper提供了这么一套机制,你可以监控watch节点的变化(内容更新,子节点添加,删除),然后节点变化的时候通过回调我们的监控器(watcher)来通知我们节点的实时变化。在这种机制下,我们可以很简单的做一个锁。
在单机模式,没有引入zookeeper时,我们可以通过创建一个临时文件来加锁,然后在事务处理完毕的时候,把这个临时文件删除就能代表解锁了。这种简单的加锁和解锁模式可以移植到zookeeper上,通过创建一个路径,来证明该锁已经存在,然后删除路径来释放该锁。而同时zookeeper又能支持对节点的监控,这样一来,我们在多机的情况下就能同时且实时知道锁是存在还是已经解锁了。
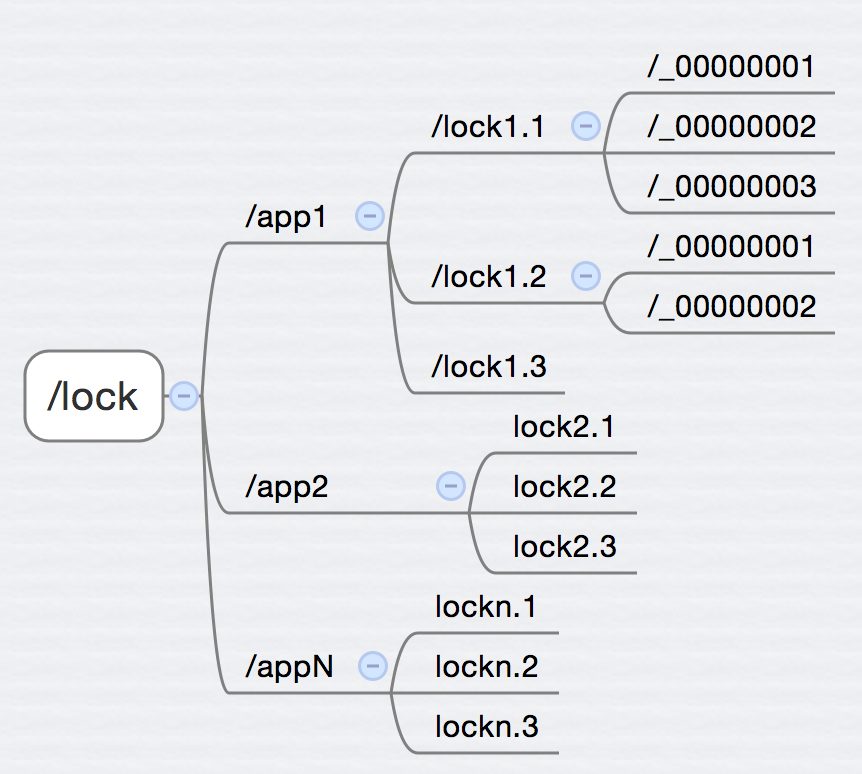
如图所示,我们在/lock下创建了/app1 /app2 … /appN n个子目录,用于适用不同的应用, 每个/app* 下面都可以根据业务需求创建锁 /lock. , 而每个机器在获取锁的时候,会在/lock. 下面创建 _0000000* 的自增长临时节点,这个节点上的数字用于表示获取锁的先后顺序。前面说的还是有点抽象,下面举个例子:
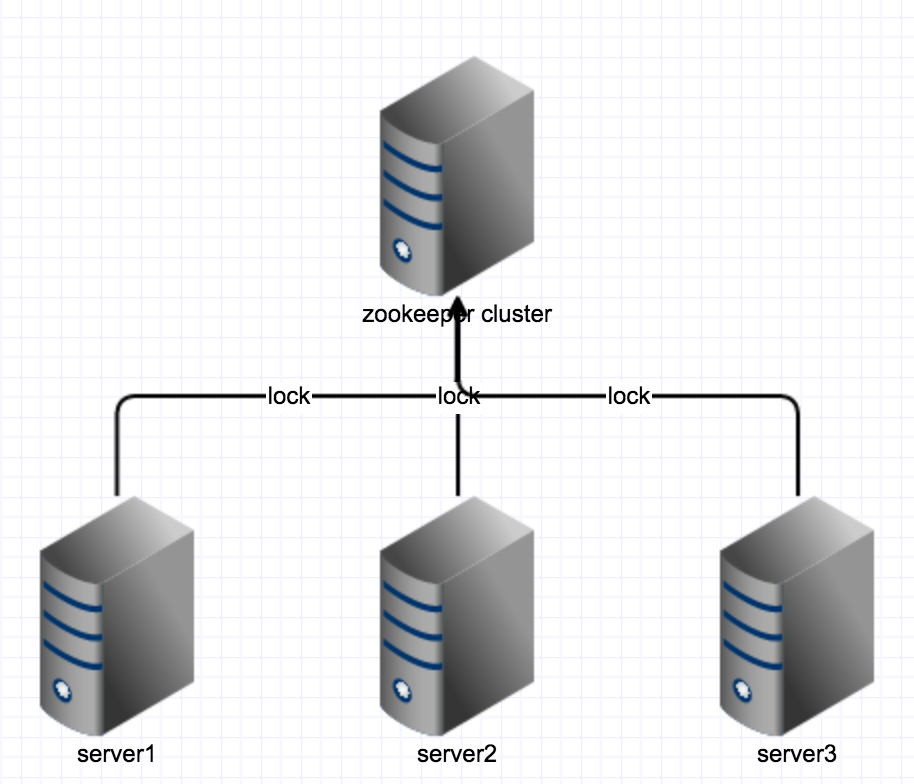
一个后台应用(app为back)总共有3台机器在处理事务,其中有一个业务(lock为 biz)同一时间只能有一台机器能处理,其他如果也同时收到处理消息的时候,需要对这个事务加个锁,以保证全局的事务性。三台机器分别表示为 server1, server2和 server3。
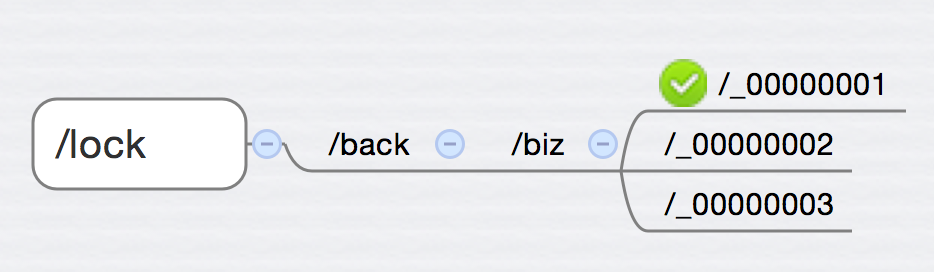
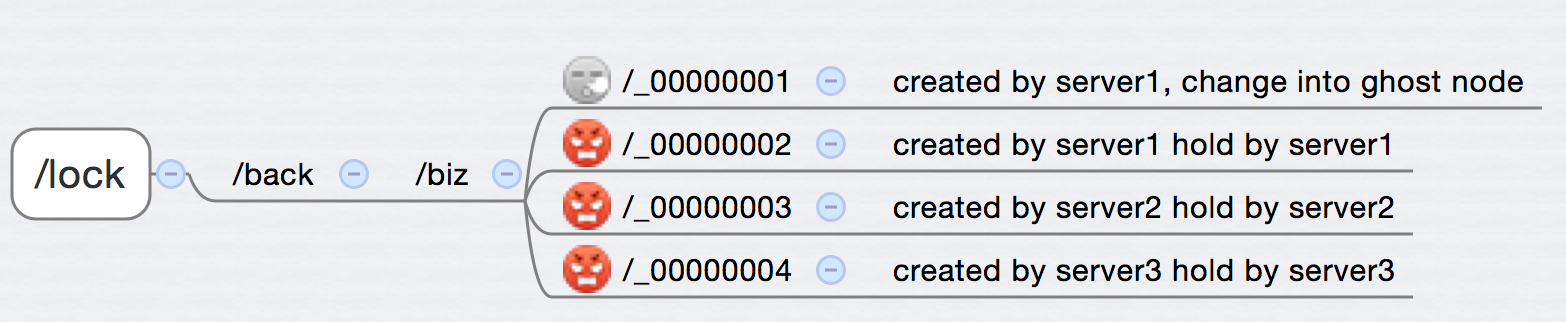
对应的,锁的路径就是 /lock/back/biz 。 首先 server1先收到消息,要处理事务biz,那么获取锁,并在/lock/back/biz下创建一个临时节点/lock/back/biz/_00000001 ,这时候判断/lock/back/biz 下的子节点,看最小的那个是不是和自己创建的相等,如果是,说明自己已经获取了锁,可以继续下一步的操作,直到事务完成。

与此同时,server2和server3也收到的消息(稍微慢于server1收到),这时候server2和server3也分别会在/lock/back/biz下面创建临时节点/lock/back/biz/_00000002 和 /lock/back/biz/_00000003,他们这时候也会判断/lock/back/biz下的子节点,发现最小的节点是_00000001,不是自己创建的那个,于是乎就会进入一个wait的操作(通过mutex很容易实现)。
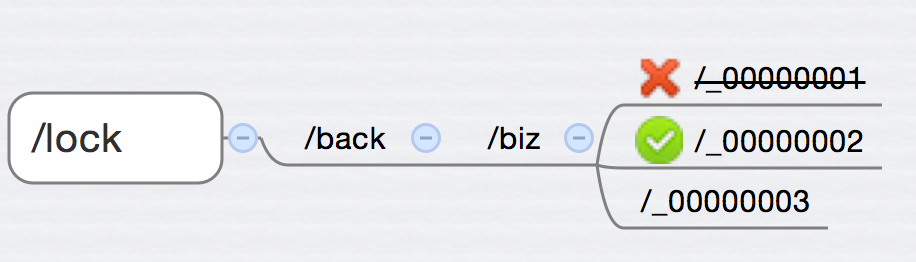
之后,等server1的事务处理完毕,释放server1获取的锁,也就是把 /_00000001删掉。由于zookeeper可以监控节点的变化,删掉/_00000001的时候,zookeeper可以通过节点删除的事件,通知到server1 server2 server3,这时候server2和server3对上面通过mutex block住的区块发送信号量(notify),server2和server3继续进入判断/lock/back/biz下面的子节点以及最小的节点和自己做对比,这时候server2由于创建了节点_00000002,所以轮到他来获取锁:
之后server2开始进入事务处理,然后释放锁,server3开始得到锁,处理事务,释放锁。以此类推。
这样一来,整个事务(biz)的处理就能保证同时只有一台机能处理到了。
整体伪代码如下:
public class LockImpl{
//获取zk实例,最好是单例的或者是共享连接池,不然并发高的时候,容易挂
private Zookeeper zk = getZookeeper();
//用于本地做wait和notify
private byte[] mutex = new byte[0];
//节点监控器
private Watcher watcher;
//这个锁生成的序列号
private String serial;
public LockImpl(){
watcher = new DefaultWatcher(mutex);
createIfNotExist();
}
private createIfNotExist(){
String path = buildPath();
//创建路径,如果不存在的话
createIfNotExsitPath(path);
//注册监控器,才能监控到。
registWatcher(watcher);
}
public void lock(){
//获取序列号,其实就是创建一个当前path下的临时节点,zk会返回该节点的值
String serial = genSerial();
while(true){
//获取子节点
List<string> children = getChildren();
//按从小到大排序
sort(children);
//如果当前节点是第一个,说明被当前进程的线程获取。
if(children.index(serial) == 0){
//you get the lock
break;
}else{
//否则等待别人删除节点后通知,然后进入下一次循环。
synchronized(mutex){
mutex.wait();
}
}
}
return;
}
public void unlock(){
//删除子节点就能解锁
deletePath(serial);
}
public void isLock(){
//判断路径下面是否有子节点即可
return ifHasChildren();
}
}
//监控器类
public class DefaultWatcher implements Watcher{
private byte[] mutex;
public DefaultWatcher(byte[] mutex){
this.mutex = mutex;
}
public void process(WatchedEvent event){
synchronized (mutex) {
mutex.notifyAll();
}
}
}
至此,一个看起来优雅一点的分布式锁就实现了。这是一个理想状态下的实现,咋看起来没问题,其实里面隐藏了比较严重的问题。就是这里把zookeeper理想化了,认为他是完美的,不会出现问题。这里说的问题倒不是一定是zk的bug,比如网络问题,在分布式系统中,网络问题是一个很常见的问题,很容易就会有异常的情况。如果出现网络问题,会出现什么情况呢?答案是“死锁”。
下面按多种情况来分析这个问题:
当我们向zk发起请求,要求创建一个临时节点的时候,发生了异常(包括网络异常,zk的session失效等)
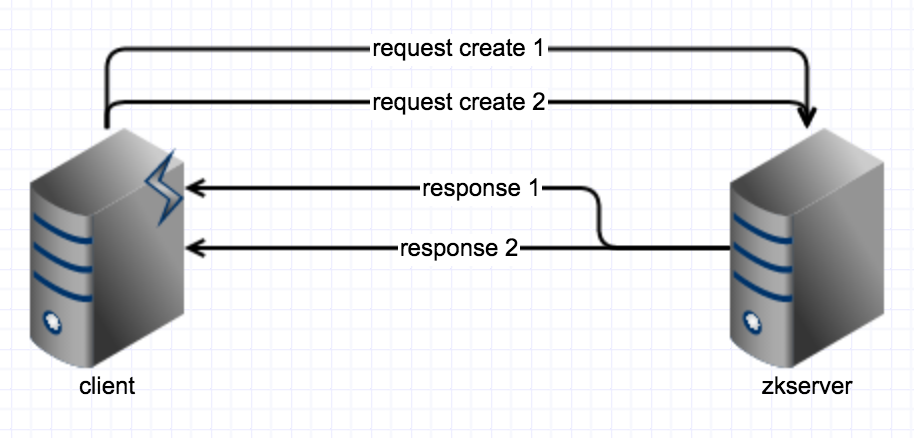
- 假设zk的服务端还没收到请求,这时候很简单,我们客户端做一下重连和重新创建就可以了,问题不大。
-
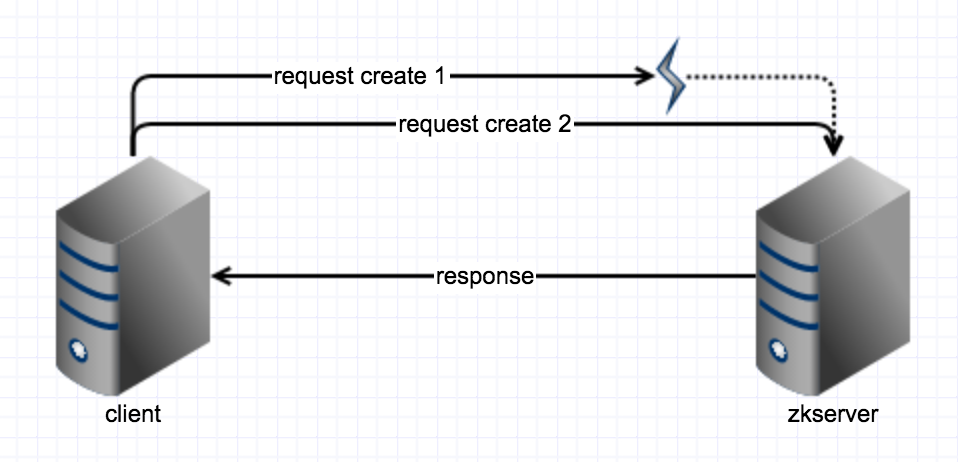
假设zk服务端收到请求了,但服务端发生异常,没有创建成功,那么我们客户端再次重试一下就可以了。

-
假设zk服务端收到了请求,子节点创建成功了,但是返回给客户端的时候网络发生了异常。这时候我们要是再做重试,创建的话,就会进入“死锁”。这里的“死锁”跟我们平时理解的死锁不是一个概念,这里的意思不是回路循环等待,而是相当于这个锁就是死掉了,因为前面的异常请求中其实创建了一个节点,然后这个节点没有客户端与他关联,我们可以称为
幽灵节点。这个幽灵节点由于先后顺序,他是优先级最高的,然而没有客户端跟他关联,也就是没有客户端可以释放这个幽灵节点,那么所有的客户端都会进入无限的等待,造成了“死锁”的现象。
-
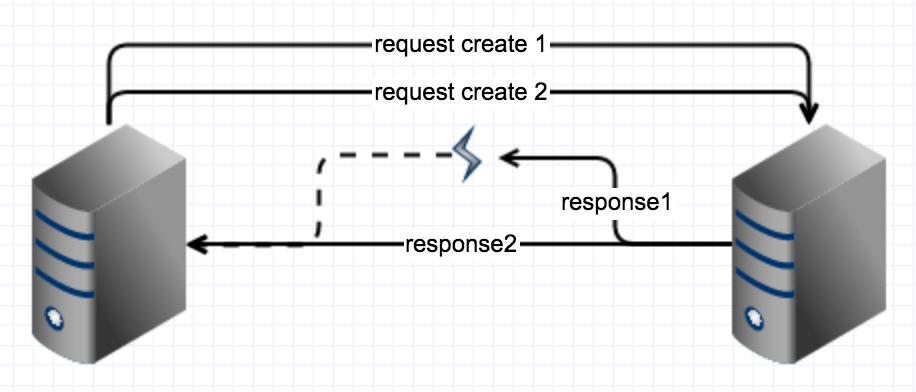
假设zk服务端收到请求了,子节点创建成功了,返回给客户端成功了,但是客户端在处理的时发生了异常(这种一般是zk的bug才会出现),这时候我们再做一次重试,也会进入上面的“死锁”现象。
为什么会出现3,4的现象呢?因为我们只是做了简单的重试,并没有对服务端和客户端做验证。就是客户端创建了一个幽灵节点,但是创建者本身甚至都不知道是自己创建的幽灵节点,还是别人创建的。要如何规避这个问题呢?废话,引入验证的流程。就是验证+无限重试。怎么做验证,不要把验证想的太复杂,验证就是你创建的节点里面有你创建的私有的信息,你客户端本身也拥有这个信息,然后两者一对比,就能知道哪个节点是哪个客户端创建的。当然,这个信息必须保证我有你无的,也就是唯一性。简单了,引入UUID就可以搞定这个问题。
1. 创建临时节点之前,客户端先生成一个UUID,(直接用JDK的UUID.randomUUID().toString()就可以了)。
2. 创建临时节点时,把这个uuid作为节点的一部分,创建出一个临时节点。
3. 重试创建的流程中加入对已存在的UUID的判断,对于是当前进程创建的子节点不再重复创建。
4. 对children排序的时候,把uuid去除后再排序,就能达到先进先出的效果。
比如客户端1,生成了UUID: fd456c28-cc85-4e2f-8d52-bcf7538a2acf, 然后创建了一个临时节点: /lock/back/biz/_fd456c28-cc85-4e2f-8d52-bcf7538a2acf_00000001
这时候服务端返回异常,拿客户端第一件事是先把children捞出来,然后判断这些children里面有没有自己创建的 uuid,如果有的话,说明自己其实是创建成功了,然后就看是不是轮到自己了,解决3的问题。如果返回正常,但是客户端有bug抛异常了,这时客户端仍要进行重试,重试之前也会走前面的流程,可以解决4的问题。
对children排序不能简单的把node的路径进行排序,因为randomUUID是完全随机的,按这个排序可能会导致某些锁请求一直没有被响应,也会有问题。这里因为UUID的长度是固定的,而且也有规律可循,所以很容易从node中分解出 uuid和序列号,然后对序列号进行排序,找出最小的值,再赋予锁,就可以了。
分布式系统中,异常出现很正常,如果你的业务需要觅等操作(N^m = N)的话,就需要引入验证和重试的机制。分布式锁就是需要一个觅等的操作,所以一个靠谱的分布式锁的实现,验证和重试的机制是少不了的,这就是我想说的。具体要参考实现的话,可以看netflix开源的zk客户端框架curator2, 比直接用zk简单得多也健壮得多。框架里面也实现了一套分布式锁(还有其他各种有用的东西),生产线其实可以直接拿来使用的,非常方便。
有必要看一下ZK了