java thread的运行周期中, 有几种状态, 在 java.lang.Thread.State 中有详细定义和说明:
NEW 状态是指线程刚创建, 尚未启动
RUNNABLE 状态是线程正在正常运行中, 当然可能会有某种耗时计算/IO等待的操作/CPU时间片切换等, 这个状态下发生的等待一般是其他系统资源, 而不是锁, Sleep等
BLOCKED 这个状态下, 是在多个线程有同步操作的场景, 比如正在等待另一个线程的synchronized 块的执行释放, 或者可重入的 synchronized块里别人调用wait() 方法, 也就是这里是线程在等待进入临界区
WAITING 这个状态下是指线程拥有了某个锁之后, 调用了他的wait方法, 等待其他线程/锁拥有者调用 notify / notifyAll 一遍该线程可以继续下一步操作, 这里要区分 BLOCKED 和 WATING 的区别, 一个是在临界点外面等待进入, 一个是在理解点里面wait等待别人notify, 线程调用了join方法 join了另外的线程的时候, 也会进入WAITING状态, 等待被他join的线程执行结束
TIMED_WAITING 这个状态就是有限的(时间限制)的WAITING, 一般出现在调用wait(long), join(long)等情况下, 另外一个线程sleep后, 也会进入TIMED_WAITING状态
TERMINATED 这个状态下表示 该线程的run方法已经执行完毕了, 基本上就等于死亡了(当时如果线程被持久持有, 可能不会被回收)
下面谈谈如何让线程进入以上几种状态:
1. NEW, 这个最简单了,
static void NEW() {
Thread t = new Thread ();
System. out.println(t.getState());
}
输出NEW
2. RUNNABLE, 也简单, 让一个thread start, 同时代码里面不要sleep或者wait等
private static void RUNNABLE() {
Thread t = new Thread(){
public void run(){
for(int i=0; i<Integer.MAX_VALUE; i++){
System. out.println(i);
}
}
};
t.start();
}

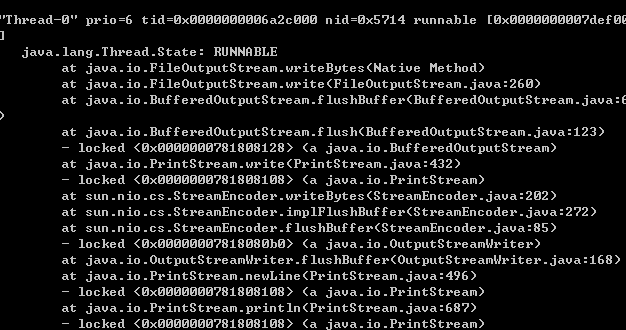
3. BLOCKED, 这个就必须至少两个线程以上, 然后互相等待synchronized 块
private static void BLOCKED() {
final Object lock = new Object();
Runnable run = new Runnable() {
@Override
public void run() {
for(int i=0; i<Integer.MAX_VALUE; i++){
synchronized (lock) {
System. out.println(i);
}
}
}
};
Thread t1 = new Thread(run);
t1.setName( “t1”);
Thread t2 = new Thread(run);
t2.setName( “t2”);
t1.start();
t2.start();
}
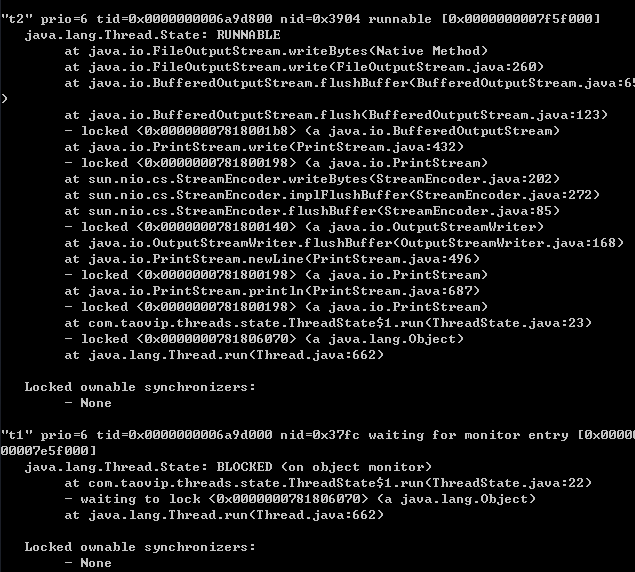
这时候, 一个在RUNNABLE, 另一个就会在BLOCKED (等待另一个线程的 System.out.println.. 这是个IO操作, 属于系统资源, 不会造成WAITING等)
4. WAITING, 这个需要用到生产者消费者模型, 当生产者生产过慢的时候, 消费者就会等待生产者的下一次notify
private static void WAITING() {
final Object lock = new Object();
Thread t1 = new Thread(){
@Override
public void run() {
int i = 0;
while(true ){
synchronized (lock) {
try {
lock.wait();
} catch (InterruptedException e) {
}
System. out.println(i++);
}
}
}
};
Thread t2 = new Thread(){
@Override
public void run() {
while(true ){
synchronized (lock) {
for(int i = 0; i< 10000000; i++){
System. out.println(i);
}
lock.notifyAll();
}
}
}
};
t1.setName( “^^t1^^”);
t2.setName( “^^t2^^”);
t1.start();
t2.start();
}

5. TIMED_WAITING, 这个仅需要在4的基础上, 在wait方法加上一个时间参数进行限制就OK了.
把4中的synchronized 块改成如下就可以了.
synchronized (lock) {
try {
lock.wait(60 * 1000L);
} catch (InterruptedException e) {
}
System. out .println(i++);
}
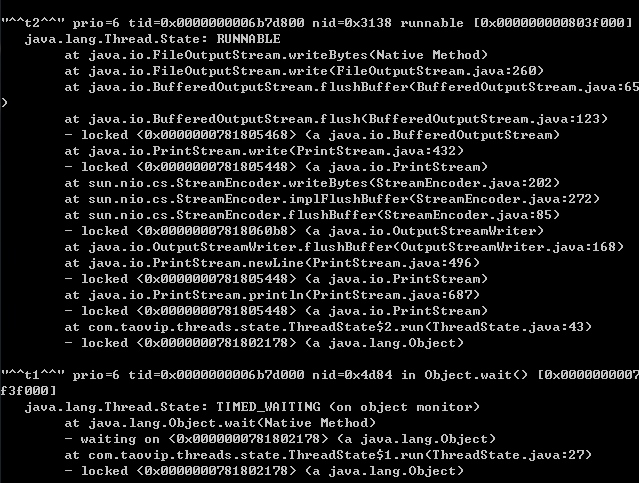
另外看stack的输出, 他叫 TIMED_WAITING(on object monitor) , 说明括号后面还有其他的情况, 比如sleep, 我们直接把t2的for循环改成sleep试试:
synchronized (lock) {
try {
sleep(30*1000L);
} catch (InterruptedException e) {
}
lock.notifyAll();
}
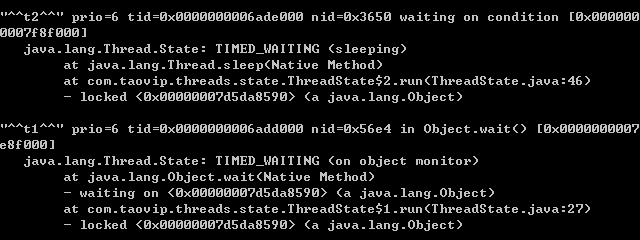
看到了吧, t2的state是 TIMED_WAITING( sleeping), 而t1依然是on object monitor , 因为t1还是wait在等待t2 notify, 而t2是自己sleep
另外, join操作也是进入 on object monitor
6. TERMINATED, 这个状态只要线程结束了run方法, 就会进入了…
private static void TERMINATED() {
Thread t1 = new Thread();
t1.start();
System. out.println(t1.getState());
try {
Thread. sleep(1000L);
} catch (InterruptedException e) {
}
System. out.println(t1.getState());
}
输出:
RUNNABLE
TERMINATED
由于线程的start方法是异步启动的, 所以在其执行后立即获取状态有可能才刚进入RUN方法且还未执行完毕
废话了这么多, 了解线程的状态究竟有什么用?
所以说这是个钓鱼贴么…
好吧, 一句话, 在找到系统中的潜在性能瓶颈有作用.
当java系统运行慢的时候, 我们想到的应该先找到性能的瓶颈, 而jstack等工具, 通过jvm当前的stack可以看到当前整个vm所有线程的状态, 当我们看到一个线程状态经常处于
WAITING 或者 BLOCKED的时候, 要小心了, 他可能在等待资源经常没有得到释放(当然, 线程池的调度用的也是各种队列各种锁, 要区分一下, 比如下图)
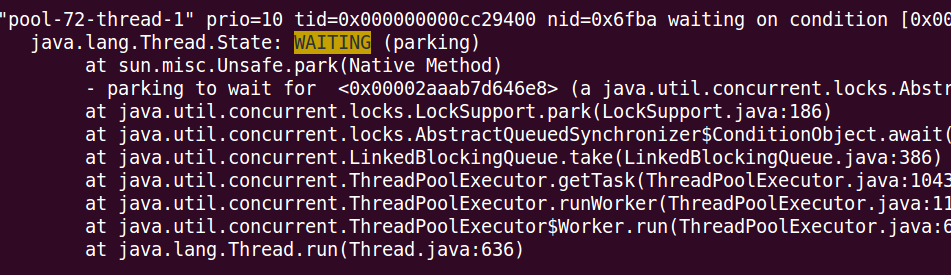
这是个经典的并发包里面的线程池, 其调度队列用的是LinkedBlockingQueue, 执行take的时候会block住, 等待下一个任务进入队列中, 然后进入执行, 这种理论上不是系统的性能瓶颈, 找瓶颈一般先找自己的代码stack,再去排查那些开源的组件/JDK的问题
排查问题的几个思路:
0. 如何跟踪一个线程?
看到上面的stack输出没有, 第一行是内容是 threadName priority tid nid desc
更过跟踪tid, nid 都可以唯一找到该线程.
1. 发现有线程进入BLOCK, 而且持续好久, 这说明性能瓶颈存在于synchronized块中, 因为他一直block住, 进不去, 说明另一个线程一直没有处理好, 也就这个synchronized块中处理速度比较慢, 然后再深入查看. 当然也有可能同时block的线程太多, 排队太久造成.
2. 发现有线程进入WAITING, 而且持续好久, 说明性能瓶颈存在于触发notify的那段逻辑. 当然还有就是同时WAITING的线程过多, 老是等不到释放.
3. 线程进入TIME_WAITING 状态且持续好久的, 跟2的排查方式一样.
上面的黑底白字截图都是通过jstack打印出来的, 可以直接定位到你想知道的线程的执行栈, 这对java性能瓶颈的分析是有极大作用的.
NOTE: 上面所有代码都是为了跟踪线程的状态而写的, 千万不要在线上应用中这么写…